切换导航
{{systemName}}
{{ info.Title }}
{{info.Title}}
{{ menu.Title }}
{{menu.Title}}
登录
|
退出
搜索
C# .NET6或.NET Framework4.7 TesseractOCR 图片文字识别
作者:ych
### 使用介绍 C#版本源码下载地址:https://github.com/charlesw/tesseract 其实在vs中可以直接用NuGet工具进行下载: 打开nuget,搜索tesseract,点安装即可。 #### 英文识别代码 ``` using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System.Text; using System.Threading.Tasks; using System.Windows.Forms; using Tesseract; namespace TesseractDemo { public partial class Form1 : Form { public Form1() { InitializeComponent(); } //选图片并调用ocr识别方法 private void btnRec_Click(object sender, EventArgs e) { //openFileDialog1.Filter = ""; if (openFileDialog1.ShowDialog() == DialogResult.OK) { var imgPath = openFileDialog1.FileName; pictureBox1.Image=Image.FromFile(imgPath); string strResult = ImageToText(imgPath); if (string.IsNullOrEmpty(strResult)) { txtResult.Text = "无法识别"; } else { txtResult.Text = strResult; } } } //调用tesseract实现OCR识别 public string ImageToText(string imgPath) { using (var engine = new TesseractEngine("tessdata", "eng", EngineMode.Default)) { using (var img = Pix.LoadFromFile(imgPath)) { using (var page = engine.Process(img)) { return page.GetText(); } } } } } } ``` #### 中英文混合识别 ``` private void button1_Click(object sender, EventArgs e) { // 设置Tesseract引擎的数据文件路径 string tessDataPath = $@"{AppContext.BaseDirectory}\tessdata"; // 设置要识别的图像文件路径 string imagePath = $@"{AppContext.BaseDirectory}\1.png"; // 初始化Tesseract引擎 using (var engine = new TesseractEngine(tessDataPath, "chi_sim+eng", EngineMode.Default)) { // 从图像文件中读取文本 using (var img = Pix.LoadFromFile(imagePath)) { using (var page = engine.Process(img)) { // 输出识别结果 textBox1.Text = page.GetText(); } } } } ``` #### tessdata训练集介绍 ``` osd.traineddata eng.traineddata chi_sim_vert.traineddata chi_sim.traineddata ``` ##### chi_sim.traineddata `chi_sim.traineddata`是`Tesseract OCR`引擎中用于识别简体中文文本的训练数据文件。在`Tesseract`中,每种语言都需要一个单独的训练数据文件,用于指导引擎识别该语言的文本。 ##### chi_sim_vert.traineddata `chi_sim_vert.traineddata`是`Tesseract OCR`引擎中用于识别简体中文(竖排)文本的训练数据文件。与横排的简体中文相比,竖排的简体中文是按照竖直方向书写的,每个字以及连续的字组成的词语都是竖直排列的。 ##### eng.traineddata `eng.traineddata`是`Tesseract OCR`引擎中用于识别英文文本的训练数据文件。在`Tesseract`中,每种语言都需要一个单独的训练数据文件,用于指导引擎识别该语言的文本。 ##### osd.traineddata `osd.traineddata`是`Tesseract OCR`引擎中的一个重要文件,用于方向和脚本检测(`Orientation and Script Detection`)。在Tesseract中,除了针对特定语言的训练数据文件之外,还有一些用于辅助识别的训练数据文件。 这个文件包含了一些用于检测文本方向和脚本(语言)的模型和规则。在进行文本识别之前,Tesseract通常会先使用这些模型来检测图像中文本的方向(例如,是水平的还是倾斜的)以及所使用的脚本(例如,拉丁文、中文、阿拉伯文等)。 通过在`Tesseract`初始化时指定osd参数,可以启用方向和脚本检测功能。示例代码中的`chi_sim+eng`表示同时使用中文简体和英语进行识别,而`osd`则是用于方向和脚本检测。 ### 更多比如识别身份证 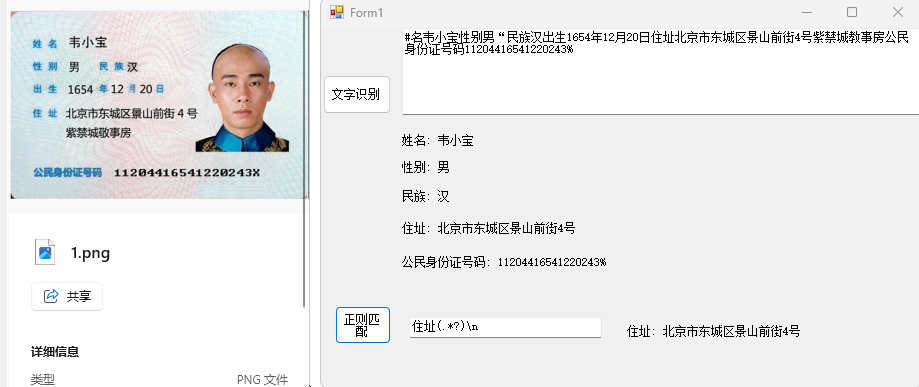 ``` private void button1_Click(object sender, EventArgs e) { // 设置Tesseract引擎的数据文件路径 string tessDataPath = $@"{AppContext.BaseDirectory}\tessdata"; // 设置要识别的图像文件路径 string imagePath = $@"{AppContext.BaseDirectory}\1.png"; // 初始化Tesseract引擎 using (var engine = new TesseractEngine(tessDataPath, "chi_sim+eng", EngineMode.Default)) { // 从图像文件中读取文本 using (var img = Pix.LoadFromFile(imagePath)) { using (var page = engine.Process(img)) { // 输出识别结果 textBox1.Text = page.GetText().Replace(" ", ""); // 提取姓名 string namePattern = @"姓名(.*?)\n"; string name = Regex.Match(textBox1.Text, namePattern).Groups[1].Value.Trim(); if (string.IsNullOrWhiteSpace(name)) { namePattern = @"名(.*?)\n"; name = Regex.Match(textBox1.Text, namePattern).Groups[1].Value.Trim(); } // 提取性别 string genderPattern = @"性别(.*?)“"; string gender = Regex.Match(textBox1.Text, genderPattern).Groups[1].Value.Trim(); if (string.IsNullOrWhiteSpace(gender)) { genderPattern = @"别(.*?)“"; gender = Regex.Match(textBox1.Text, genderPattern).Groups[1].Value.Trim(); } // 提取民族 string nationalityPattern = @"民族(.*?)\n"; string nationality = Regex.Match(textBox1.Text, nationalityPattern).Groups[1].Value.Trim(); if (string.IsNullOrWhiteSpace(nationality)) { nationalityPattern = @"族(.*?)\n"; nationality = Regex.Match(textBox1.Text, nationalityPattern).Groups[1].Value.Trim(); } // 提取住址 string addressPattern = @"住址(.*?)\n"; string address = Regex.Match(textBox1.Text, addressPattern).Groups[1].Value.Replace("\n","").Trim(); if (string.IsNullOrWhiteSpace(address)) { addressPattern = @"址(.*?)\n"; address = Regex.Match(textBox1.Text, addressPattern).Groups[1].Value.Trim(); } // 提取公民身份证号 string idPattern = @"\d{17}[\dXx%]"; string idNumber = Regex.Match(textBox1.Text, idPattern).Value; // 输出结果 label1.Text = "姓名: " + name; label2.Text = "性别: " + gender; label3.Text = "民族: " + nationality; label4.Text = "住址: " + address; label5.Text = "公民身份证号码: " + idNumber; } } } } private void button2_Click(object sender, EventArgs e) { string addressPattern = textBox2.Text; string address = Regex.Match(textBox1.Text, addressPattern).Groups[1].Value.Replace("\n", "").Trim(); label6.Text= "住址: " + address; } ``` #### 其他方案 https://blog.csdn.net/wxgxgp/article/details/78061729 或 https://www.cnblogs.com/cnsec/p/13286777.html 或 https://gitee.com/xgpxg/ICRS (它有源码) ### git地址 [模型数据地址](https://github.com/tesseract-ocr/tessdata "地址")
评论区
先去登录
版权所有:机遇屋在线 Copyright © 2021-2025 jiyuwu Co., Ltd.
鲁ICP备16042261号-1