切换导航
{{systemName}}
{{ info.Title }}
{{info.Title}}
{{ menu.Title }}
{{menu.Title}}
登录
|
退出
搜索
秘籍列表
ASP.NET基础及企业项目应用
必备工具的安装及C#基础的介绍
ASP.NET高级
数据库操作
Web前端基础
ASP.NET建站核心
ASP.NET MVC
.Net项目
ASP.NET 数据库及各种ORM使用教程
面试
数据库操作
[TOC] 这里我直接以开源数据库MySQL来给大家讲,这个是学习难度相对中等的数据库。目前的数据库市场显然是一副三足鼎立的架势,Oracle,MySql,Sql Server占据了大半个江山。 首先说一下Sql Server微软的亲儿子,用起来可以说最简单易学的数据库,在学校大家普遍学习的数据库,只适合小型企业而且windows平台可靠性、安全性和伸缩性非常有限,虽然我的个人项目使用的该数据库,但是简单易学并且限制比较多,并且不开源。 其次再说一下Oracle甲骨文公司的亲儿子,比较方便,支持多操作系统,也是由于公司系统架构复杂数据量较大迁移不易.....该花的钱还得花,不过确实好用,主要是对硬件要求高,价格也非常昂贵。 最后说MySql可以说是甲骨文的干儿子,一款完全开源的数据库,体积小、速度快、总体拥有成本低,跨平台,适合中小企业,及有一定技术实力的大企业,也有缺点不支持热备份;MySQL最大的缺点是其安全系统,主要是复杂而非标准,另外只有到调用mysqladmin来重读用户权限时才发生改变;没有一种存储过程(Stored Procedure)语言,这是对习惯于企业级数据库的程序员的最大限制。 由于2008年阿里首先提出了去O,之后互联网公司也渐渐走向了去O的道路。现在三种数据库都很流行, 会了Oracle发现Mysql简单一些, 传统行业基本以Oracle为主, 而互联网行业则MySQL当道,分布式存储用mysql方便,mysql经过这么多年本身也成熟,比如备份、主备库、有经验的MYSQL的dba,mysql开源,有技术资源的大公司可以定制开发些东西,因此我决定以MySql来给大家讲数据库知识,希望大家可以一通百通。 [【第三章数据库基本知识(数据库基础教学)视频】](https://www.bilibili.com/video/BV1uW411o7oU/?share_source=copy_web&vd_source=160a6bb7aac774f8784a54ccad1255a1 "【第三章数据库基本知识(数据库基础教学)视频】") ####第一节必备工具的安装 #####Mysql安装(Windows) (1)先从网站下载安装包,如果找不到就到[机遇屋](https://www.jiyuwu.com/Article/ShowArticle/57 "机遇屋")下的开发包汇总下载下载Mysql装包。 (2)下载完的程序包进行安装数据库: 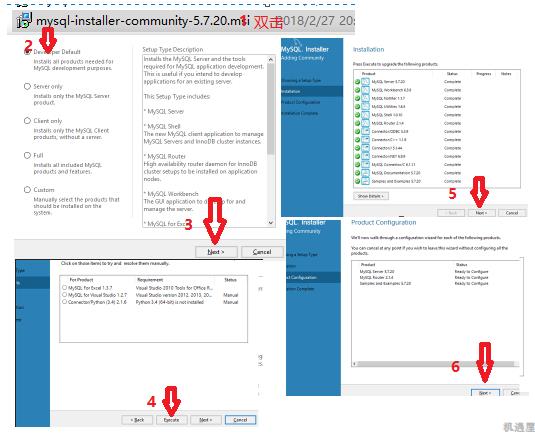 (3)设置数据库并创建用户: 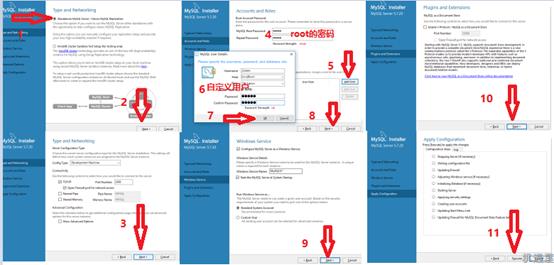 (4)配置并检查用户: 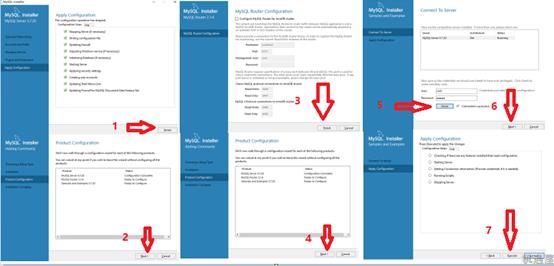 (5)完成安装: 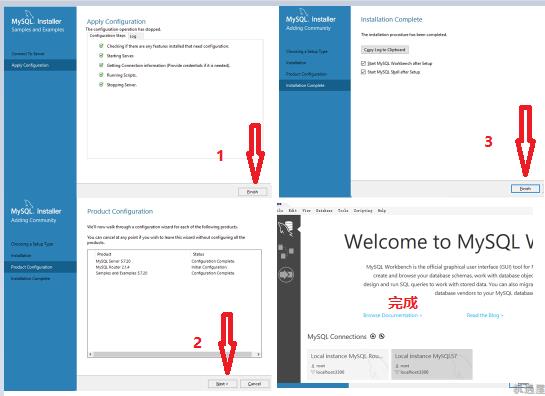 这样数据库就安装完成了。 (6)测试连接: 从CMD命令行输入mysql -u 你的用户 -p 回车 输入你的密码后得到如下图界面表示安装成功: 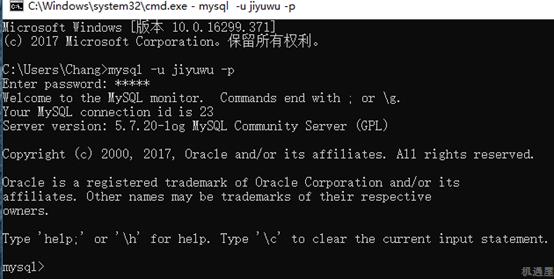 ####第二节用户管理及数据库操作 #####1. 数据库操作 (1)查看数据库: ``` SHOW DATABASES; ``` (2)创建数据库: ``` CREATE DATABASE db_name; //db_name为数据库名 ``` (3)使用数据库: ``` USE db_name; ``` (4)删除数据库: ``` DROP DATABASE db_name; ``` #####2.用户管理 (1)新建用户: ``` CREATE USER name IDENTIFIED BY '12345'; ``` (2)更改密码: ``` SET PASSWORD FOR name=PASSWORD('123456'); ``` (3)权限管理: ``` SHOW GRANTS FOR name; //查看name用户权限 GRANT SELECT ON db_name.* TO name; //给name用户db_name GRANT ALL PRIVILEGES ON db_name.* TO name; //给name用户db_name所有操作权限 ``` (4)数据库的所有权限: ``` REVOKE SELECT ON db_name.* FROM name; //GRANT的反操作,去除权限; ``` ####第三节创建与修改表 #####1.创建表 (1)创建表: ``` CREATE TABLE table_name(id TINYINT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY, //id值,无符号、非空、递增——唯一性,可做主键。 name VARCHAR(60) NOT NULL, title VARCHAR(60) , score TINYINT UNSIGNED NOT NULL DEFAULT 0//设置默认列值 )ENGINE=InnoDB //设置表的存储引擎,一般常用InnoDB和MyISAM;InnoDB可靠,支持事务;MyISAM高效不支持全文检索 DEFAULT charset=utf8; //设置默认的编码,防止数据库中文乱码 如果有条件的创建数据表还可以使用 >CREATE TABLE IF NOT EXISTS tb_name(........) ``` (2)复制表: ``` CREATE TABLE tb_name2 SELECT * FROM tb_name; 或者部分复制: CREATE TABLE tb_name2 SELECT id,name FROM tb_name; ``` (3)创建临时表: ``` CREATE TEMPORARY TABLE tb_name(这里和创建普通表一样); ``` (4)查看数据库中可用的表: ``` SHOW TABLES; ``` (5)查看表的结构: ``` DESCRIBE tb_name; ``` 也可以使用: ``` SHOW COLUMNS in tb_name; //from也可以 ``` (6)删除表: ``` DROP [ TEMPORARY ] TABLE [ IF EXISTS ] tb_name[ ,tb_name2.......]; ``` 实例: ``` DROP TABLE IF EXISTS tb_name; ``` (7)表重命名: ``` RENAME TABLE name_old TO name_new; ``` 还可以使用: ``` ALTER TABLE name_old RENAME name_new; ``` #####2.修改表结构 ``` 更改表结构: ALTER TABLE tb_name ADD[CHANGE,RENAME,DROP] ...要更改的内容... 实例: ALTER TABLE tb_name ADD COLUMN address varchar(80) NOT NULL; ALTER TABLE tb_name DROP address; ALTER TABLE tb_name CHANGE score score SMALLINT(4) NOT NULL; ``` ####第四节增删改数据 #####1. 插入数据: (1)插入数据: ``` INSERT INTO tb_name(id,name,score)VALUES(NULL,'张三',140),(NULL,'张四',178),(NULL,'张五',134); ``` 这里的插入多条数据直接在后边加上逗号,直接写入插入的数据即可;主键id是自增的列,可以不用写。 (2)插入检索出来的数据: ``` INSERT INTO tb_name(name,score) SELECT name,score FROM tb_name2; ``` #####2. 删除数据: (1)删除数据: ``` DELETE FROM tb_name WHERE id=3; ``` #####3. 更新数据: (1)指定更新数据: ``` UPDATE tb_name SET score=189 WHERE id=2; UPDATE tablename SET columnName=NewValue [ WHERE condition ] ``` ####第五节视图 #####1.视图作用 (1)简化表之间的联结(把联结写在select中); (2)重新格式化输出检索的数据(TRIM,CONCAT等函数); (3)过滤不想要的数据(select部分) (4)使用视图计算字段值,如汇总这样的值。 #####2.创建或覆盖视图 (1)创建视图: ``` CREATE VIEW v_tb_name AS SELECT * FROM tb_name WHERE ~~ ORDER BY ~~; ``` (2)覆盖视图: ``` create or replace view v_tb_name (id,bz,name) as select id, title, name from tb_name; ``` (3)删除视图: ``` DROP VIEW [IF EXISTS] v_tb_name; ``` ####第六节存储过程 存储过程就是一个自定义函数,有局部变量参数,可传入参数,可以返回值。 #####1.创建存储过程: ``` delimiter // -- 末尾不要符号 “;” CREATE PROCEDURE pro( IN num INT,OUT total INT) BEGIN SELECT SUM(score) INTO total FROM tb_name WHERE id=num; END; // IN (传递一个值给存储过程),OUT(从存储过程传出一个值),INOUT(对存储过程传入、传出),INTO(保存变量) ``` #####2.调用存储过程: ``` CALL pro(13,@total) //这里的存储过程两个变量,一个是IN一个是OUT,这里的OUT也是需要写上的,不写会出错 SELECT @total //这里就可以看到结果了; ``` #####3.存储过程的其他操作: (1)查询当前的存储过程: ``` SHOW PROCEDURE STATUS; //显示当期的存储过程 ``` (2)删除指定存储过程: ``` DROP PROCEDURE pro; //删除指定存储过程 ``` (3)游标可以以编程的方式访问数据库但是在创建游标时,最需要考虑的事情是,“是否有办法避免使用游标?”因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该改写;如果使用了游标,就要尽量避免在游标循环中再进行表连接的操作。由于游标使用弊端太大这里我就不讲了,感兴趣请自行百度。 ####第七节触发器 #####1. 触发器介绍和使用场景 (1) 触发器是指在进行某项指定操作时,触发触发器内指定的操作; (2)支持触发器的语句有DELETE、INSERT、UPDATE,其他均不支持。 #####2.创建触发器 ``` delimiter // CREATE TRIGGER tg_name after insert on tb_name for Each row begin insert into tb_name10(id,name,title,score) values(new.id,new.name,new.title,new.score); end; ``` INSERT语句,触发语句,会触发。 #####3. 删除触发器 ``` DROP TRIGGER trig; ``` ####第八节事务 #####1. 事物的介绍: (1)特性: 原子性 (Atomicity) 、一致性 (Consistency) 、隔离性 (Isolation) 、持久性 (Durability)。 (2)意义: 事务中的所有操作要么全部执行,要么都不执行; 如果事务没有原子性的保证,那么在发生系统 故障的情况下,数据库就有可能处于不一致状态。 #####2. 使用事务的两种方式 (1)方法一: ``` BEGIN; //开始事务,挂起自动提交 insert into tb_name (id, title, name, score) values(null, ‘赵家装’,’赵六’, 88); insert into tb_name10 (id, title, name, score) values(null, ‘赵家装’,’赵六’, 89); COMMIT; //提交事务,恢复自动提交 ``` (2)方法二: ``` set autocommit = 0; //挂起自动提交 insert into tb_name (id, title, name, score) values(null, ‘赵家装’,’赵六’, 88); insert into tb_name10 (id, title, name, score) values(null, ‘赵家装’,’赵六’, 89); COMMIT; //提交事务 set autocommit = 1; //恢复自动提交 ``` ####第九节查询基础 #####1.WHERE条件查询 ``` SELECT * FROM tb_name WHERE id=3; ``` #####2. HAVING条件分组查询 ``` SELECT * FROM tb_name GROUP BY score HAVING count(*)>2 ``` #####3. 查询排序 (1) 降序排序: ``` SELECT * FROM tb_name ORDER BY DESC; ``` (2) 升序排序: ``` SELECT * FROM tb_name ORDER BY ASC; ``` #####4. 相关条件控制符查询 (1)范围查询: ``` =、>、<、<>、IN(1,2,3......)、BETWEEN a AND b、NOT IN(2,3) ``` (2)多条件筛选: ``` AND 、OR ``` (3)模糊查询: ``` Like()用法中 % 为匹配任意、 _ 匹配一个字符(可以是汉字) ``` (4)空值检测: ``` IS NULL 空值检测 ``` (5)REGEXP的正则表达式(特殊字符需要转义)查询: ``` SELECT * FROM tb_name WHERE name REGEXP '^[A-D]' //找出以A-D 为开头的name ``` ####第十节查询提高 #####1. 去重 (1)distinct唯一性查询: ``` SELECT distinct name, id from tb_name; ``` 扩展:union去除重复的方式等效于distinct关键字,它是指输出字段列表的组合无重复。 (2)嵌套查询去重: ``` SELECT * FROM tb_name a WHERE ((SELECT COUNT(*) FROM tb_name WHERE Title = a.Title) > 1) ORDER BY Title DESC; ``` (3)过滤重复记录(只显示一条): ``` Select * From tb_name Where ID In (Select Max(ID) From tb_name Group By Title) ``` #####2. MySQL的一些函数 (1)字符串链接——CONCAT(): ``` SELECT CONCAT(name,'=>',score) FROM tb_name ``` (2)数学函数: ``` AVG、SUM、MAX、MIN、COUNT; ``` (3)文本处理函数: ``` TRIM、LOCATE、UPPER、LOWER、SUBSTRING ``` (4)运算符: ``` +、-、*、\ ``` (5)时间函数: ``` DATE()、CURTIME()、DAY()、YEAR()、NOW()..... ```
上一篇
下一篇
版权所有:机遇屋在线 Copyright © 2021-2025 jiyuwu Co., Ltd.
鲁ICP备16042261号-1